Abstract
Representing 3D shape in deep learning frameworks in an accurate, efficient and compact manner still remains an open challenge. Most existing work addresses this issue by employing voxel-based representations. While these approaches benefit greatly from advances in computer vision by generalizing 2D convolutions to the 3D setting, they also have several considerable drawbacks. The computational complexity of voxel-encodings grows cubically with the resolution thus limiting such representations to low-resolution 3D reconstruction. In an attempt to solve this problem, point cloud representations have been proposed. Although point clouds are more efficient than voxel representations as they only cover surfaces rather than volumes, they do not encode detailed geometric information about relationships between points. In this paper we propose a method to learn free-form deformations (FFD) for the task of 3D reconstruction from a single image. By learning to deform points sampled from a high-quality mesh, our trained model can be used to produce arbitrarily dense point clouds or meshes with fine-grained geometry. We evaluate our proposed framework on synthetic data and achieve state-of-the-art results on surface and volumetric metrics.
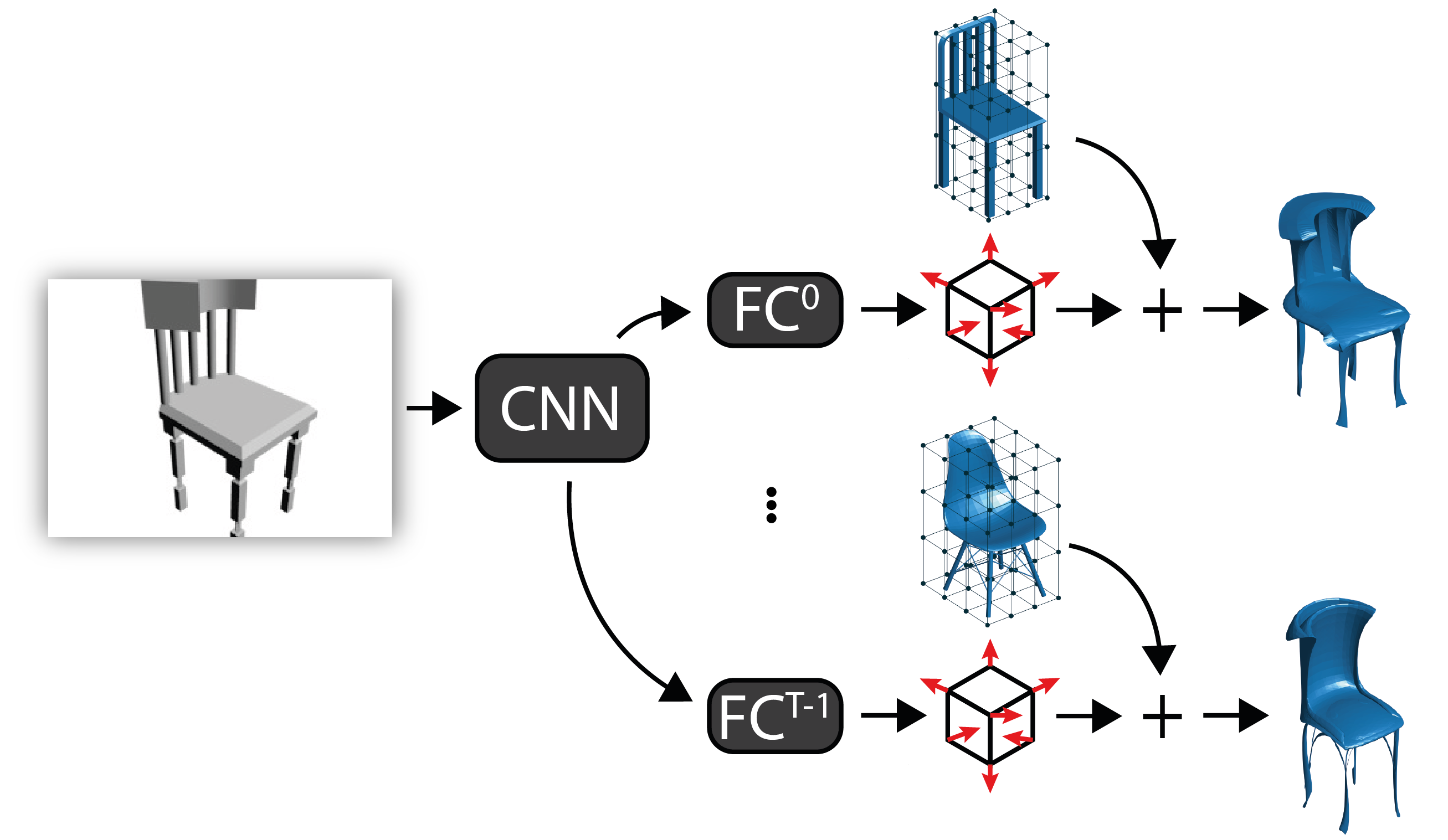
Overview
Given a single image, our method uses a CNN to infer free-form deformation (FFD) parameters $\Delta \mathbf{P}$ (red arrows) for multiple templates $T$ (middle meshes). The $\Delta \mathbf{P}$ parameters are then used to deform the template vertices to infer a 3D mesh for each template (right meshes). Trained only with surface-sampled point-clouds, the model learns to apply large deformations to topologically different templates to produce inferred meshes with similar surfaces. Likelihood weightings $\gamma$ are also inferred by the network but not shown for simplicity. FC stands for fully connected layer.
Results
Representative results for different categories. Column (a) shows the input image. Column (b) shows the selected template model. Column (c ) shows the deformed point cloud by FFD. The deformed voxelized model is shown in column (d). Column (e) shows our final 3D mesh reconstruction, and the ground truth is shown in column (f).
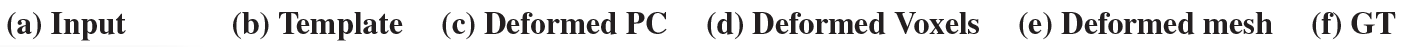

Transferring 3D semantic labels
Good (left block) and bad (right block) examples from the chair and plane categories. For each block: Input image; selected template’s semantically segmented cloud; deformed segmented cloud; deformed mesh.
